(Class B volumetric glassware has ±mL tolerances twice those
of
Class A glassware)
| Capacity
(mL) |
Transfer
pipets
(E969) |
Micro-
volumetric
vessels
(E237) |
Measuring
pipets
(E1293) |
Volumetric
flasks
(E288) |
Burets
(E287) |
Graduated
cylinders
(E1272) |
| 0.5 |
0.006 |
|
|
|
|
|
| 1 |
0.006 |
0.010 |
0.01 |
|
|
|
| 2 |
0.006 |
0.015 |
0.01 |
|
|
|
| 3 |
0.01 |
0.015 |
|
|
|
|
| 4 |
0.01 |
0.020 |
|
|
|
|
| 5 |
0.01 |
0.020 |
0.02 |
0.02 |
|
0.05 |
| 6 |
0.01 |
|
|
|
|
|
| 7 |
0.01 |
|
|
|
|
|
| 8 |
0.02 |
|
|
|
|
|
| 9 |
0.02 |
|
|
|
|
|
| 10 |
0.02 |
0.020 |
0.03 |
0.02 |
0.02 |
0.10 |
| 15 |
0.03 |
|
|
|
|
|
| 20 |
0.03 |
|
|
|
|
|
| 25 |
0.03 |
0.030 |
0.05 |
0.03 |
0.03 |
0.17 |
| 30 |
0.03 |
|
|
|
|
|
| 40 |
0.05 |
|
|
|
|
|
| 50 |
0.05 |
|
|
0.05 |
0.05 |
0.25 |
| 100 |
0.08 |
|
|
0.08 |
0.10 |
0.50 |
| 200 |
|
|
|
0.10 |
|
|
| 250 |
|
|
|
0.12 |
|
1.00 |
| 500 |
|
|
|
0.20 |
|
2.00 |
| 1000 |
|
|
|
0.30 |
|
3.00 |
| 2000 |
|
|
|
0.50 |
|
6.00 |
Even with this stringent standard, during the period 1995-1999 we encountered one buret
with an
internal defect. It appeared to be a small fragment of unmelted glass which produced an internal
bump in the bore. During the calibration process one would expect such a defect to cause a
serious systematic error in the delivered volume.
Any glassware used for quantitative measurements is a potential source of systematic error.
Pipettes, burets, graduated cylinders and even graduated beakers fall into this category. From
time to time one observes mislabeled graduations on burets which could lead the technician to
erroneous procedures.
Where more sophisticated equipment is used, namely electronic measuring apparatus,
systematic
errors can come about as the result of low batteries, poor contacts within the device, sensitivity to
temperature and humidity and even mechanical defects in the case of meter movements.
One's methods are threatened with systematic errors as well. A reaction which comes to
completion slowly, an indicator whose color change occurs well before or after the equivalence
point of a reaction, a step which is particularly cumbersome or requires meticulous attention to
detail (the transfer of the barium sulfate precipitate in the gravimetric analysis experiment), a step
which one might wish to perform to a fault (excessively washing the barium sulfate with water
until peptization and subsequent loss of precipitate through the filter paper) all carry the peril of
systematic error.
Consider some of the areas prone to systematic errors in our other experiments:
| Carbonate determination |
Copper in Brass |
Manganese in Steel |
| Failure to boil the solution at
the final end point |
Failure to dissolve all of the
copper in the brass |
Failure to dissolve all of the
steel sample |
| Failure to do a blank reading |
Adding too much 3M sulfuric
acid subsequently producing a
pH which is too low |
Not filtering out unwanted
particles |
| Use of an indicator with an
end point well before or well
after the equivalence point. |
Not removing all of the
nitrogen oxides after solution
of the brass |
Not oxidizing all carbon
granules. |
A more serious systematic error often comes about because the method is not universally
applicable. The Kjeldahl method for the determination of nitrogen in plant and animal tissues
depends on a digestion by concentrated H2SO4. Nitrogens which
yield
to such a digestion are -NH2 and -NH- groups. But fully bound nitrogen atoms, in
the form of =N-, are often
incompletely digested. Thus there is a tendency for the determination to give a low result.
The investigator often contributes to systematic errors by routinely reading instrument scales
high
or low or developing preconceived notions of an anticipated result and reading the instrument
scales so as to improve the results.
An investigator who is asked to weigh three samples to ±0.0001 grams and to make the
weight in
the vicinity of 3.0 g might consciously try to make each sample as close to 3.0000 g as can be
managed by scooping off excess sample or adding more in tiny increments. Such a technique
risks errors in weight due to spillage on the pan but outside the container holding the sample and
also by the absorption of moisture from the air. A buret reading based upon a starting point of
0.00 mL can lead to systematic errors if the same convention for the relative location of .10, .20,
.30 mL and so on is not the same as that used for 0.00. One ought to decide on the top, the
middle or the bottom of the width of the calibration mark. Finally, when interpolating the
volume
reading of a buret between 0.30 and 0.40, for example, some people tend to favor 0.30, 0.35 and
0.40 mL over some other number which on close examination might be better than any of these
three.
Errors which are constant vs. those which are proportional
Constant Errors
In the gravimetric determination of sulfate, a precipitate of BaSO4 is developed
in a 400 mL
(approx.) solution. One would expect in the transfer process that the same perils for loss of
sample are present at all stages. Thus one would expect that approximately the same amount of
barium sulfate might be lost regardless of the mass of the sample. A constant error is one which
does not change with the size of the sample. It stands to reason then that a large sample weight
would be preferred over a small sample weight, because such a constant error will produce a
smaller relative error when using a
larger sample.
Exercise 6-1
If 0.8 mg barium sulfate is lost during an average transfer of the precipitate, compare the
relative
errors which would be realized if the precipitate weighed
(a) 0.8000 g and
(b) 0.4000 g.
(To be solved in class with attention paid to the magnitude of the two relative errors)
The amount of titrant necessary to produce a color change is another example of a constant
error.
Exercise 6-2
If no blank correction is made in a typical carbonate titration, what is the relative error in
parts per
thousand of a titration requiring (a) 10.00 mL, (b) 20.00 mL, (c) 30.00 mL? Assume that the
blank correction would be -0.05 mL.
(To be solved in class)
Instrumental errors often are systematic in nature. If a constant error is suspected in an
instrument which produces a reading that is directly proportional to some concentration of an
analyte, a plot can reveal such a constant error, as the following example attempts to
demonstrate:
Exercise 6-3
Five concentrations of potassium permanganate are prepared and the absorbances read at a
wavelength of 525 mµ. Beer's Law predicts that A= epsilon x c, or that absorbance is
directly
proportional to concentration, and is a constant called the molar absorptivity. Plot the values of
absorbance vs. concentration in ppm and determine the constant error in these measurements.
| ppm Mn as
KMnO4(aq) |
Absorbance |
| 5.00 |
0.272 |
| 8.00 |
0.405 |
| 10.00 |
0.515 |
| 15.00 |
0.755 |
| 20.00 |
1.015 |
Question: What are the possible explanations for the error observed in the plot of this group
of
measurements?
Proportional Errors
A proportional error is any error which is proportional to the quantity of sample.
Contaminants
which interfere with the reaction to be used in analysis are prime candidates for the production of
proportional errors because the absolute size of the error increases with the size of the sample.
The presence of iron in a sample of brass can interfere with the reduction of copper as shown in
the following two equations:
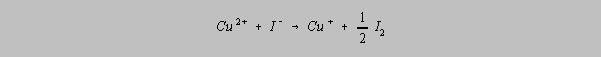
and
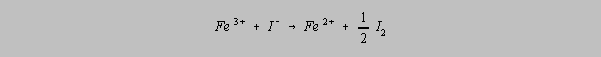
It is for this reason
that precautions must be taken to prevent this interference. Fe3+ complexes with
the phosphate ion, PO43- , in a manner that removes it from
availability
for reduction.
Finally, there are personal errors against which, sadly, there is no vaccination. Care,
self-discipline and a meticulous attention to detail need to be exercised at all times in the
laboratory to
protect oneself against personal errors.
Detection of Systematic Errors Germaine to the Method.
Systematic errors characteristic of the method used may be revealed by using the method to
analyze a standard sample. The National Institute of Standards and Technology maintains a site
at
http://ts.nist.gov. Within that site is located the entire catalog of Standard Reference
Materials. It is located at
http://ts.nist.gov/ts/htdocs/230/232/232.htm
You ought to visit this site at least once to take some measure of the level of precision
attempted
by the NIST to offer the highest quality reference materials. For example, one of the links shows
a list of meticulously prepared Single Element Standard Solutions. They are intended as standard
solutions for use in calibrating instruments used in atomic spectroscopy as well as in conjunction
with any other analytical technique or procedure where aqueous standard solutions are required.
A certificate of analysis accompanies each standard solution.
The certificate one receives starts out as follows:

For this lot the certificate includes the information that the certified value of arsenic is
8.44 mg/g±0.03 mg/gm, the method of preparation, the impurities and their amounts
(65 mg/kg total
metallic impurities and 375 mg/kg dissolved gases). There is an expiration date approximately
two
years in advance for this particular certificate and a promise to notify the purchaser should there
be
a change in the conditions of certification.
The reputation of the NIST in preparing Standard Reference Materials remains the highest in
the
world. Each of the materials is prepared and/or analyzed using one or more of the following
strategies:
(1) the use of a previously validated reference method,
(2) an analysis using two or more independently reliable measurement methods, and
(3) multiple analyses by a network of cooperating laboratories, each with a record of
technical
competence and reliability.
Should standard samples for a particular target material not be available, laboratories quite
often enter
into joint agreements to spend some fraction of their time in independent sample analysis using
sufficiently different methods for the same sample so as to diminish the chances that the same
potential mistakes will be repeated.
Statistical Tests for the Evaluation of the Reliability of Experimental Data
Not infrequently one is faced with a small number of experimental values which, owing to
some gross
error, don't belong with the others. It is interesting to reflect on the fact that the results obtained
by
an undetected loss of a portion of one's sample would be indistinguishable from some malicious
altering of a sample so as to contain less of an analyte than the sample originally set to be
analyzed.
Both would result in an analysis previously shown to be reliable in a measured quantity
considerably
less than the other samples in the group. The population is
defined
as all possible samples analyzed
by the same method without externally imposed systematic errors, either loss of sample or
maliciousness. Any such a perturbation of the analysis would place the affected sample in
another
population. But is there a method to assist the investigator in going the extra distance to obtain
an
objective reason to exclude a sample from consideration? There are two strategies which may be
followed. First, it is generally agreed upon that if a known error was made in an analysis, the
result
ought to be discarded, regardless of its relative size in comparison to the other results. Secondly,
there is a widely used statistical test, the Q-test to aid the investigator in deciding what may
safely
be discarded within certain confidence limits.
One finds widely divergent opinions about the rejection of data. Deming, an authority in the
industrial
application of statistics has said that, "a point is never to be excluded on statistical grounds
alone."
Others agree with Parratt, who writes, "rejection on the basis of a hunch or of general fear is not
at
all satisfactory, and some sort of objective criterion is better than none." The objective criterion
we
use is referred to as a Confidence Level, or Confidence Interval. A conservative confidence level
of
99% means that of all experimentally determined values within a population which lie within a
Gaussian Distribution, only 1% of all legitimate values would be
expected to fall outside this level
of confidence. That is, one tends to consider practically all points as legitimate, hence a
conservative
approach to keeping data -- the conservative approach is to keep practically everything, whereas a
confidence level of 90% would be one in which 10% of all
legitimate values would lie outside this level. Since in the minds
of
many investigators 10% represents a significant percentage of all values
determined and the rejection of this large number of otherwise carefully determined values is
viewed
to be excessive, even rash, radical, revolutionary, perhaps hare-brained, a compromise is made at
the
95% confidence level. We shall predominately use this confidence level though our tables offer
a
number of other confidence levels. Even here, some values which are suspicious may
not be rejected.
Natrella has noted, with no little amusement, "the only sure way to avoid publishing any 'bad'
results
is to throw away all results."(1) Before presenting the
formula to be used for the simplest case, it is
instructive to consider the situations one might encounter in an analysis. In the diagram below,
the
asterisks represent experimentally determined values on an arbitrary scale of 5.00 to 5.50, which
could represent "percent" anything, carbonate, sulfate, copper, etc.
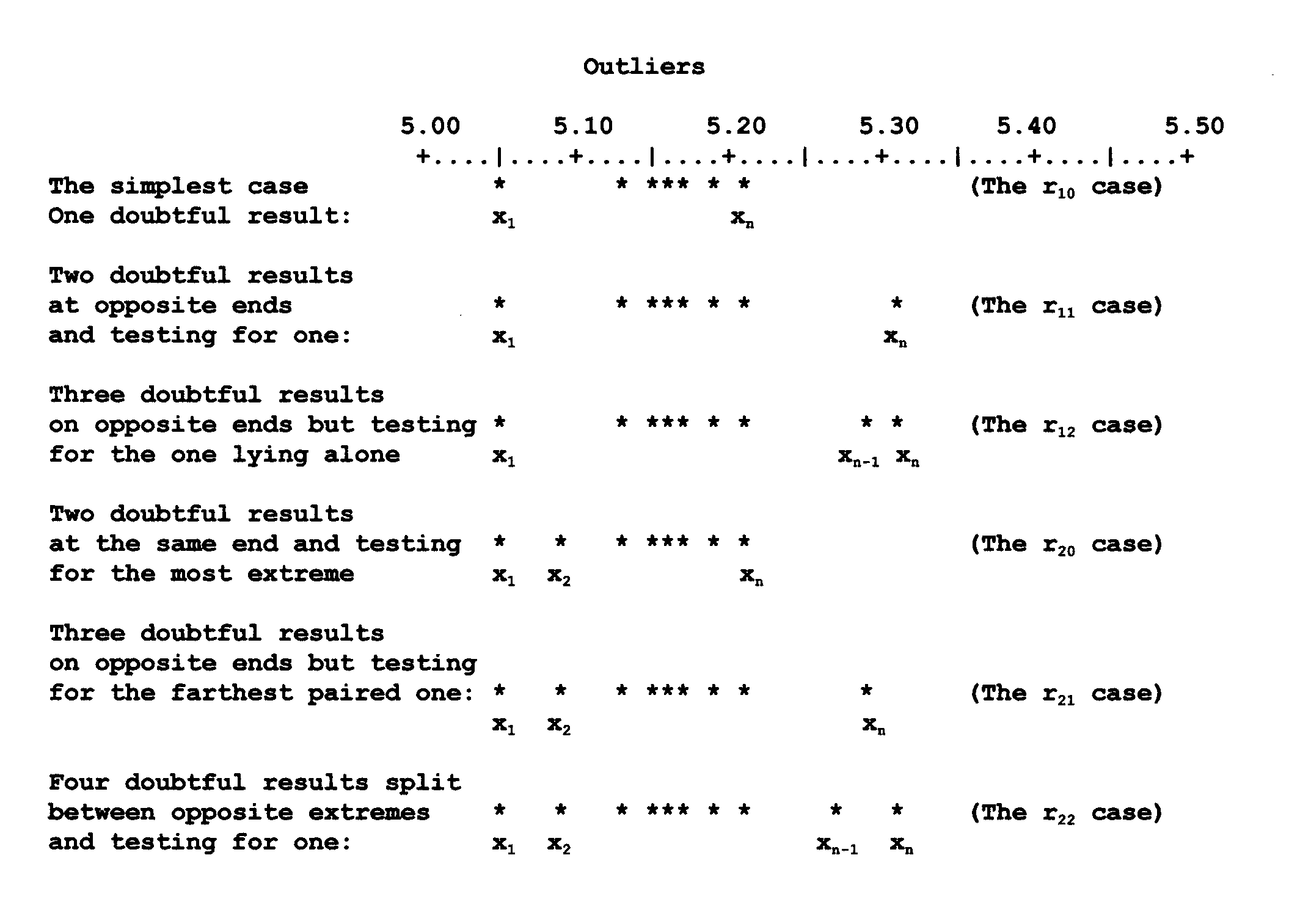
Most of the time we shall
focus on the simplest of the six tests (the r10 case) commonly available to
quantitative chemists. The tables used for all six tests are included here should the student wish
to
pursue the matter further, and because examples taken from real situations in class often force us
to
consider the other cases. The formulas used to compare a Q exp with one of
Dixon's Q Parameters precede each of the tables for which that formula is to be used. The tables
are listed at the end of this chapter.
The Q test
The simplest Q test is that in which there appears to be single
outlier, that is, a data point which does not belong to the
population of the rest of the data points. This "r10" Q-test draws on the spread,
w,
between the extreme values and the difference between the doubtful data point and its nearest
neighbor (when the values are arranged from lowest to highest). If this calculated Q
"experimental",
Qexp is greater than the value found in the table, then at the level of confidence
indicated, the value
may be discarded.
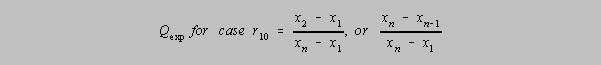
In this first variation
on the r10 formula it is assumed that there are n data elements in the group, that
x2 is the value of the nearest neighbor to the questionable value and that
x1 is the questionable value.
Should the questionable value be on the high side, as in the second variation on the right,
xn is the
questionable result, xn-1 is its nearest neighbor and the denominator is the spread of
all values.
Exercise 6-4. Read a partially filled graduated cylinder. Write down the result on a scrap of
paper
and turn in to the instructor. Don't let any of your fellow students see what you have written.
The
instructor will write the results on the board, arranged from lowest to highest. Which case does
this
fit? With what level of confidence can you reject any of the extreme values?
(To be performed in class)
Exercise 6-5. Here are similar results for one recent semester of CHE 230, written exactly as
they
were reported by students:
1995: 5.09, 5.4, 5.5, 5.57, 5.58, 5.59, 5.61
Which case does this collection of data fit? With what level of confidence can you reject the
extreme
value? (To be performed in class)
Exercise 6-6a. Here are some results obtained the following semester:
1996: 6.3, 6.385, 6.4, 6.61
Exercise 6-6b. Look at Exercise 5-12, the determination of %Cu in brass. With what level
of
confidence can you reject the two outliers in this student's data?
Which case does this collection of data fit? With what level of confidence can you reject the
extreme
value? (To be performed in class).
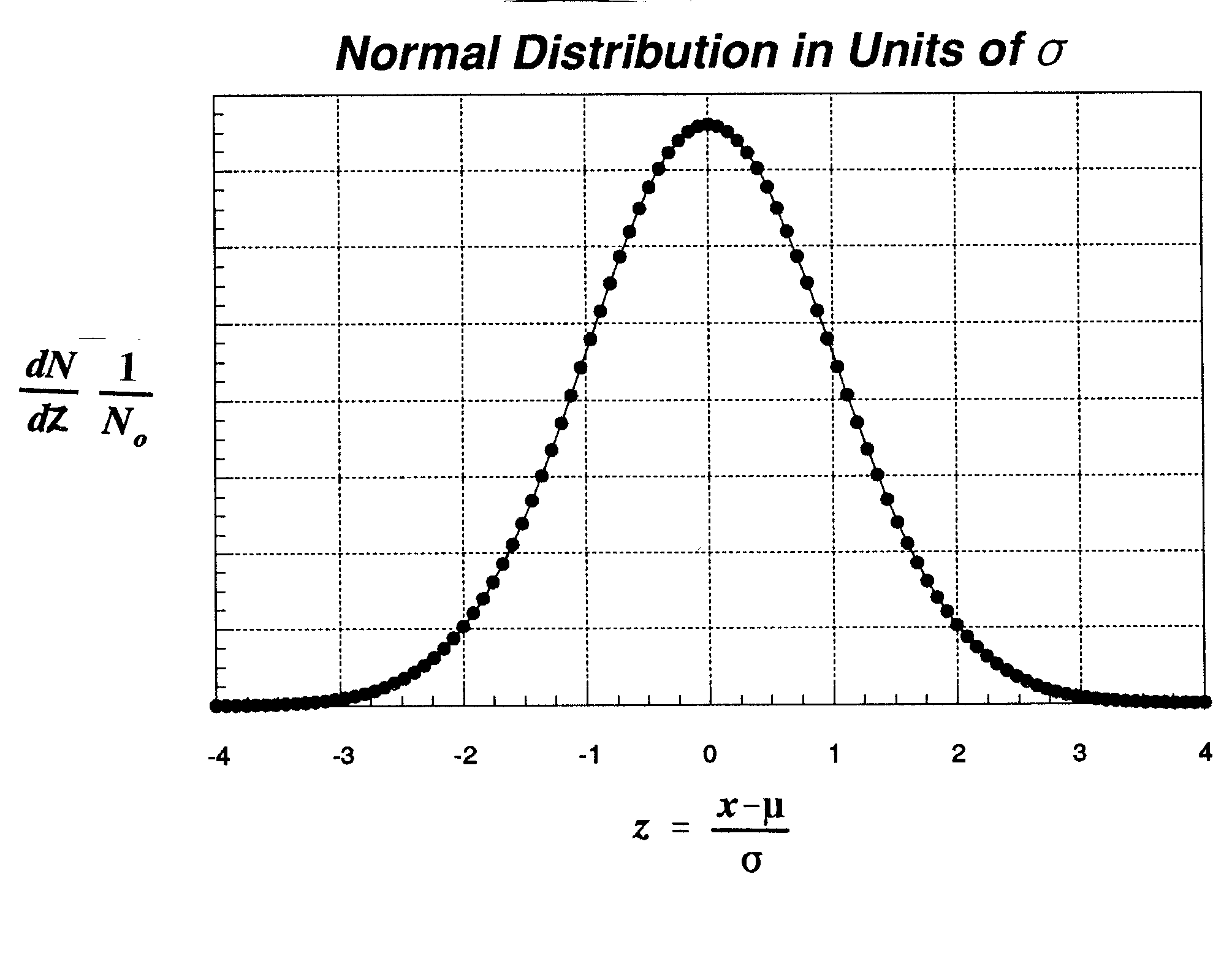
The confidence interval when the standard
deviation of your sample is a good approximation
of sigma or when your sample comes from a known population.
To recap a point about the normal distribution, the
area 1 on either side of this distribution contains
68% of the values determined. 2 contains 96% of
all values. The function you see is continuous and is
a characteristic distribution to which one extrapolates
if the population contains an infinite number of
elements, but as we have seen before, even if the total
number of events is only 10000, the shape of a normal distribution begins to be revealed.
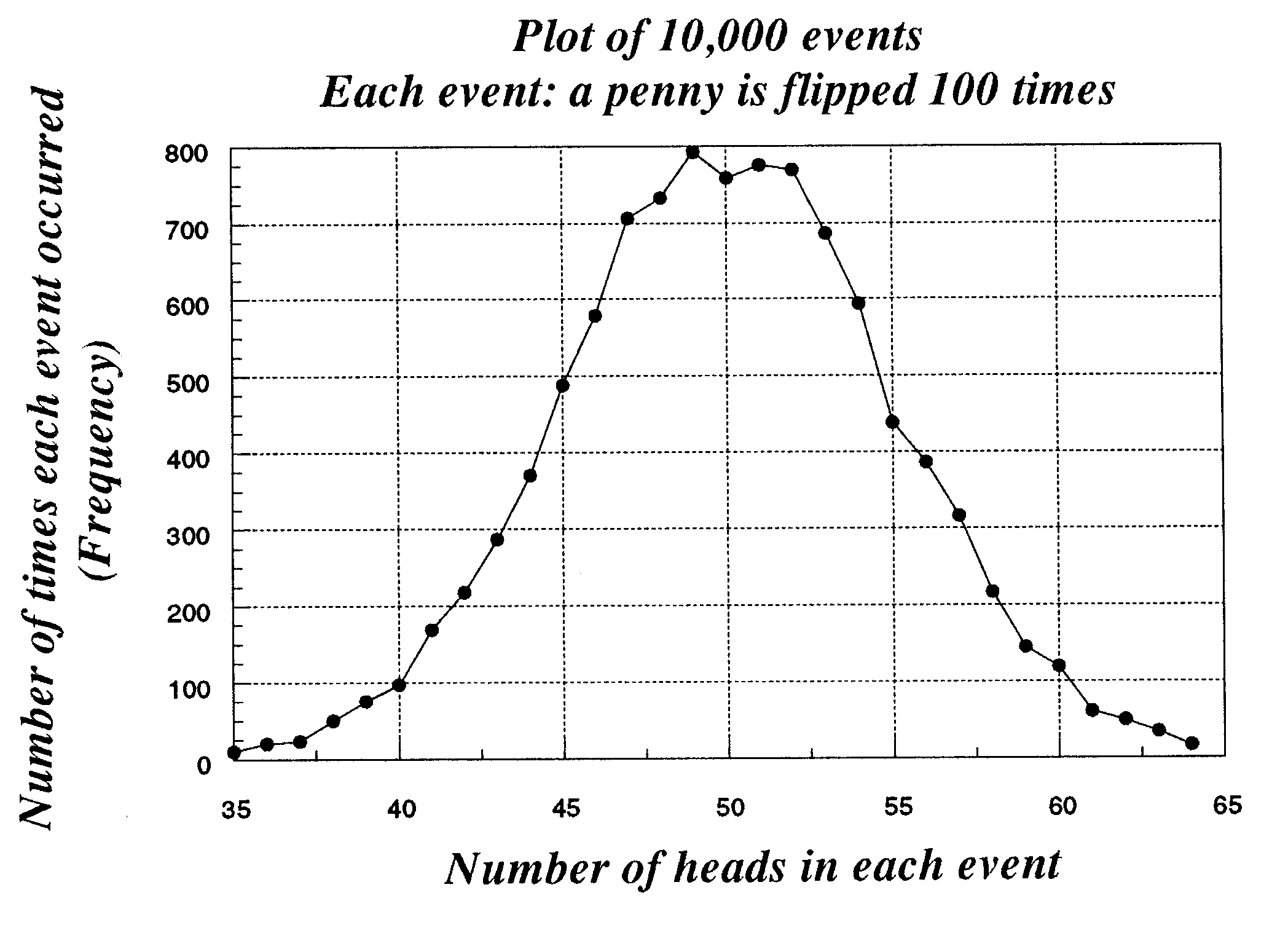 Exercise 6-7. Consider
again the plot first shown in
Chapter 5. Does it appear here that 68% of all events
will be enclosed within an interval of ±1? That 96%
of all values will be enclosed within ±2? Taking the list of values given to you in class or
which you have
calculated with one of the programs made available
to you, determine the point on either side of the mean
which encompasses 68 and 96%. Are they
sufficiently near to 1 sigma and 2 sigma to satisfy
you?
Exercise 6-7. Consider
again the plot first shown in
Chapter 5. Does it appear here that 68% of all events
will be enclosed within an interval of ±1? That 96%
of all values will be enclosed within ±2? Taking the list of values given to you in class or
which you have
calculated with one of the programs made available
to you, determine the point on either side of the mean
which encompasses 68 and 96%. Are they
sufficiently near to 1 sigma and 2 sigma to satisfy
you?
There is a strategy to determine confidence limits of
the inclusion of the mean of the population if a small sample is used but the method is well
known.
Before we get to that strategy, let's for a moment consider the "method." The "method" is often
thought to be a chemical technique, like the gravimetric determination of sulfate by precipitating
barium sulfate, or the volumetric determination of carbonate. But where statistical tests are
concerned there is a subtlety to the method which includes the technician who does the test.
Often,
if the technician is well trained, maintains always a meticulous attention to detail, has an
exemplary
background and years of experience in analytical chemistry, then this added subtlety is minimal.
It
is fair then to propose that any new
data point reported by such a technician belongs to the same
population. At least that is the assumption. So, we talk about the Confidence
Interval for µ,
the mean for that chemist's population:
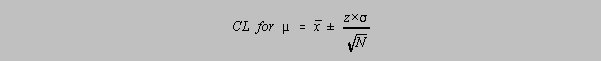
where
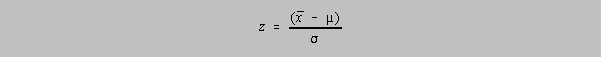
The value of z is related to the confidence limit by the area under a normal distribution at
±z:
Confidence levels for various values of z
| Confidence
Levels, % |
z |
| 50 |
0.67 |
| 68 |
1.00 |
| 80 |
1.29 |
| 90 |
1.64 |
| 95 |
1.96 |
| 96 |
2.00 |
| 99 |
2.58 |
| 99.7 |
3.00 |
| 99.9 |
3.29 |
Exercise 6-8. Turn to the appendix in chapter 5. If he remembers, the instructor will pass
out
cut-up segments of that appendix so as to assure greater randomness for the following process.
Use a pencil for this exercise. Close your
eyes, circle
the pencil around above your desk top and put the point down on the paper showing the array of
10000 events each one of which represents flipping a coin 100 times. Remembering the value of
the
standard deviation for this collection of events, determine the 90, the 95 and the 99% confidence
limits that the mean of the population lies within these limits. (To be solved in class).
Exercise 6-9. Extract the values found by two of your classmates. Determine the 90, the 95
and the
99% confidence limits that the mean of the population lies with these limits. (To be solved in
class).
Exercise 6-10. Taking all values determined by all members of the class, determine the 90,
the 95 and
the 99% confidence interval that the mean of the population lies within these limits. (To be
solved
in class).
For your consideration:
(1) A confidence interval is based on probability. We might be unlucky and by the luck of
the
draw
have values that would put us outside the envelope.
(2) Note that as the confidence limit increases, so does the envelope. The width of the
envelope is
linked to the confidence limit.
(3) As the certainty of a mean increases by an increase in the number of reported values, the
width
of the envelope decreases (the square root of N is in the denominator). This illustrates that the
greater number of
samples increases precision.
(4) The mean of a population may not be known, but its standard deviation may be available.
That is, the "population" may be a determination of the same analyte done by the same chemist
hundreds of times. The pooled standard deviation would exist as a reflection of the precision of
the method used, but there would be no "population mean." So the chemist's pooled value of
s would be indistinguishable from sigma but one wouldn't speak of the
population "mean" when the samples come from many different sources.
Another way to put a problem like that above:
Exercise 6-11: How many values would you need to decrease the 80% confidence limit to
±2? (To
be performed in class).
The Student T Test
But what if the "method" ISN'T well known? What happens if your bench chemist of 35
years has
just retired and you've had to go to a temporary employment agency to find a replacement. Your
new
chemist and the technique used is a part of the "method." And you don't know very much about
the
scatter of the method this new guy is going to offer you. So here is a situation in which sigma is
not
known and all you have to go by is a small number of samples which he analyzes. The technique
to
be used here is called Student's T Test.
Shortly after the turn of the twentieth century, a paper was published by "A. Student" which
showed
how some knowledge of a population mean could be gained if only a small sample of
experimentally
determined results was available and nothing was known about the scatter of a large number of
determinations which would be more characteristic of the population of results by some given
method. The real name of the author -- A. Student was an obvious pseudonym -- wasn't known
until
the 1950s when it was revealed that W.S. Gossett had as a young man been employed by the
Guinness Brewery. He had evidently been denied permission to publish the paper under his own
name so he did so anonymously, giving the world the Student T-Test. Some observers have
suggested that Guinness had begun to use statistical techniques such as this to improve the
company's
quality control and the company did not want its competitors to know its strategy, thus the denial
to
Gossett.
Here's another way of saying the same thing: Your new chemist does a small number of
analyses.
You don't know to which population his results belong. The Student T-test allows you to glean
some
knowledge from his experimental standard deviation.
The method goes like this: (1) Choose a value of "t" from the table for a given confidence
level. (2)
Determine the mean and standard deviation for the small sample (3) Calculate the confidence
limit
for that level of confidence from this formula:
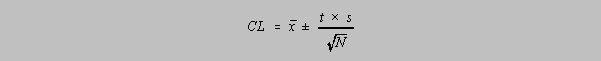
The "N" in the equation above is the number of reported values, but the value of t in the table
below is found in the row showing the number of degrees of freedom = N-1.
Values of t for various levels of probability
| Deg. of
freedom |
80% |
90% |
95% |
99% |
99.8% |
| 1 |
3.08 |
6.31 |
12.7 |
63.7 |
318. |
| 2 |
1.89 |
2.92 |
4.30 |
9.92 |
22.3 |
| 3 |
1.64 |
2.35 |
3.18 |
5.84 |
10.2 |
| 4 |
1.53 |
2.13 |
2.78 |
4.60 |
7.17 |
| 5 |
1.48 |
2.02 |
2.57 |
4.03 |
5.89 |
| 6 |
1.44 |
1.94 |
2.45 |
3.71 |
5.21 |
| 7 |
1.42 |
1.90 |
2.36 |
3.50 |
4.78 |
| 8 |
1.40 |
1.86 |
2.31 |
3.36 |
4.50 |
| 9 |
1.38 |
1.83 |
2.26 |
3.25 |
4.30 |
| 10 |
1.37 |
1.81 |
2.23 |
3.17 |
4.14 |
| 15 |
1.34 |
1.75 |
2.13 |
2.95 |
3.73 |
| 20 |
1.32 |
1.72 |
2.09 |
2.84. |
3.55 |
| 30 |
1.31 |
1.70 |
2.04 |
2.75 |
3.38 |
| 60 |
1.30 |
1.67 |
2.00 |
2.66 |
3.23 |
| inf. |
1.29 |
1.64 |
1.96 |
2.58 |
3.09 |
Exercise 6-12. Consider that you and two of your classmates each flip a coin 100 times
(well,
why
not?). Each of you gets some value for the total number of heads. Come to think of it, each of
you
has already determined such a number in the random choice exercise above. If each of you had
actually flipped a coin a hundred times and put together your results
without any knowledge of the
plot of 10000 identical events, trying to find the interval for a given level of confidence that the
population mean would be found within those limits would be a job for Student's T test. (A)
Apply
Student's t test to this situation and determine with 95% confidence how far away the population
mean might lie from the mean of your three-event sample. (B) But let's say that suddenly,
voila!,
we're told the standard deviation of the normal distribution of the 10000 events each event of
which
is a coin flip 100 times. That can be used as the sigma. The number of degrees of freedom in
such a
population is infinite our Student T-test reverts to the case in which sigma is known. Use the
standard
deviation of the population to calculate the 95% confidence interval for the mean. (To be solved
in
class).
Exercise 6-13a. Consider the results reported by Student 5 in the soda ash unknown:
| Student |
Sample 1 |
Sample 2 |
Sample 3 |
mean |
s |
| 5 |
20.88 |
20.98 |
20.81 |
20.89 |
0.09 |
With 95% confidence how far away might be the mean of this student's unknown
population?
Exercise 6-13b. What is the effect in the case of Student 5? An old professor hobbles in and
says,
"Well, it's
all well and good for Student 5 to have had three samples which showed a standard deviation of
0.09
for values having a mean of 20.89%, but I had her in my class last semester and I know with
certainty
that her work is routinely good to 2 parts per thousand, or 20.89±0.04. That being the
case, calculate
the 95% confidence interval for the mean. (To be performed in class).
Please note that Exercise 6-12 demands some consideration of the following two points.
Since the
same random number generator was used to generate the three values picked by students and
their
pencils as was used to generate all 10000, we know that there is no systematic error inherent in
the
three numbers manually picked (notwithstanding the argument that arranging the numbers in a
rectangle with the student perhaps favoring the center over the edges might prejudice the results).
Still, by the luck of the draw, the three numbers 36, 37 and 38 might have been chosen. Such a
small
standard deviation among the three would have predicted a mean far from 50. Any confidence
limit
is based on probability and it is good always to say to oneself, "Although there is a 95%
probability
that the mean lies within these limits, there is a 5% probability that it does not." Secondly, notice
that
once the population standard deviation is known, there is a narrowing of the interval for the same
confidence level.
The probability of bias in an experimental result where a true value is
known.
We've seen that there is a way to calculate the probability of finding the mean within a
certain
confidence interval if the value of sigma for a population is known (use of the table with z
values).
We've seen that if a few samples are
determined and the value of s is calculated, we can determine the
extremity of location of the mean
of an unknown population within certain confidence limits (the Student T Test). In the case
where we have a known value
of the mean of a population, or for a chemist that might mean a true value which will be µ
for a
reliable method of analysis, the question is for an unknown method (read "generally untried
technique," or "new analytical chemist" or "Carrot Top on his first day at work.") is "does it
produce
results which have bias?" This test is nearly identical to the t-test described earlier, but the
statement
one uses after all calculations have been made deserves some study and reflection. The statement
is
based on a "null" hypothesis. But first the method:
(1) On the basis of the number of analyses reported, find a t for a given level of confidence.
(2) Calculate the mean and s for the reported analyses.
(3) Calculate (the mean - µ) and compare it with
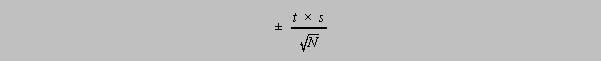
Exercise 6-14. Consider the following three reported values for the percent copper in brass
during
one recent semester:
80.47,80.62,80.32. The true value is known from the analytical laboratory which prepared
this
sample to be 82.10% Cu. Do the test for bias at the 95%, the 99% and the 99.8% confidence
levels.
(To be performed in class and get ±0.37 for 95%, ±0.859 for 99%, and ±1.931
for 99.8%
But the mean - µ = 1.63.
Here are the statements: If there were no bias,
fewer than 5 times in a hundred (95% confidence level) will an experimental mean deviate
from the
true mean by 0.37 or more.
fewer than 1 time in a hundred (99% confidence level) will an experimental mean deviate
from
the
true mean by 0.859 or more.
fewer than 2 times in one thousand (99.8% confidence level) will an experimental mean
deviate from
the true mean by 1.931 or more.
And the zinger:
If we say that 1.63 is significant and that there is systematic error we would be wrong less
than 5
times in a hundred, less than 1 time in a hundred, but more than 2
times in 1000.
Exercise 6-15. In 1997 seven CHE230 students read the volume of water in a 10 mL
graduated
cylinder and report the following values: 6.78,6.79,6.8,6.80,6.800,6.82,6.82 mL.
The instructor had previously read the volume and decided it to be 6.78 mL (the "true"
value). With
what level of confidence can one establish bias in these results? (To be performed in class)
On the other hand, if it turns out that the method used is well-known (or alternatively, that
one has
confidence that the experimental results belong to the same population which has a known
standard
deviation) then the solution is reduced to the case of the known sigma; z replaces t and sigma
replaces s.
Exercise 6-16. The instructor says, "It's reasonable to assume that these fine students can
read a 10 mL
graduated
cylinder in a manner which for many readings will give them a standard deviation of ±0.01
mL." Taking 6.78 to be "equal" to µ and replacing
t with
z, now
with what level of confidence can bias be established in these results?
The comparison of two experimental means
Finally, you are presented with two sets of results which are sufficiently far from each other
to
suggest any of the following:
(A) they come from different sources, that is the % analyte is clearly different in each.
(B) they are analyzed by two different technicians one or both of which produce a
systematic
error,
(C) or more generally, the two sets of samples come from different populations.
(1) Calculate each mean.
(2) determine a pooled standard deviation
(3) Calculate the absolute value of the difference between the two means and compare it with
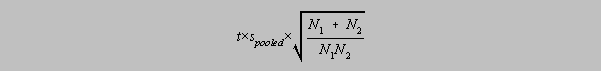
Exercise 6-17
Consider the carbonate reports from students 9 and 12:
| Student |
Sample 1 |
Sample 2 |
Sample 3 |
mean |
s |
| 9 |
48.88 |
48.83 |
48.27 |
48.66 |
0.34 |
| 12 |
50.42 |
50.38 |
50.45 |
50.42 |
0.04 |
Do a determination of bias at the 95%, 99% and 99.8% levels of confidence and make a
concluding
statement consistent with the reasoning used for a comparison of experimental values with a true
value. (To be performed in class)
Exercise 6-18
Carry out the same procedure as in Exercise 6-17 with the results of students 3 and 5:
| Student |
Sample 1 |
Sample 2 |
Sample 3 |
mean |
s |
| 3 |
22.09 |
21.74 |
21.98 |
21.94 |
0.18 |
| 5 |
20.88 |
20.98 |
20.81 |
20.89 |
0.09 |
Least Squares Linear Regression
Exercise 6-19. Consider the following table of data from the determination of Mn in steel:
| c (g/mL) |
Absorbance |
| 4.00 x 10-6 |
0.181 |
| 6.00 x 10-6 |
0.255 |
| 10.00 x 10-6 |
0.438 |
| 14.00 x 10-6 |
0.623 |
| 16.00 x 10-6 |
0.689 |
Referring to the instructions on carrying out least squares linear regression in your laboratory
manual,
determine the best slope m and y-intercept b for these data, for a plot of concentration along x
and
Absorbance along y so that the following linear relation between concentration and Absorbance
is
predicted:
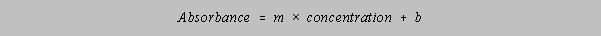
(To be solved in class).
Dixon's Q Parameters
for various arrangements of doubtful results
and for various levles of confidence from 80% to 99%(2)
r10 Q Parameter, based on one doubtful result (one outlier). If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
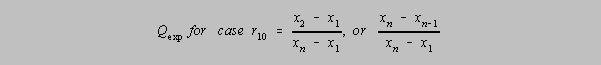
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 3 |
0.886 |
0.941 |
0.970 |
0.976 |
0.988 |
0.994 |
| 4 |
0.679 |
0.765 |
0.829 |
0.846 |
0.889 |
0.926 |
| 5 |
0.557 |
0.642 |
0.710 |
0.729 |
0.780 |
0.821 |
| 6 |
0.482 |
0.560 |
0.625 |
0.644 |
0.698 |
0.740 |
| 7 |
0.434 |
0.507 |
0.568 |
0.586 |
0.637 |
0.680 |
| 8 |
0.399 |
0.468 |
0.526 |
0.543 |
0.590 |
0.634 |
| 9 |
0.370 |
0.437 |
0.493 |
0.510 |
0.555 |
0.598 |
| 10 |
0.349 |
0.412 |
0.466 |
0.483 |
0.527 |
0.568 |
| 11 |
0.332 |
0.392 |
0.444 |
0.460 |
0.502 |
0.542 |
| 12 |
0.318 |
0.376 |
0.426 |
0.441 |
0.482 |
0.522 |
| 13 |
0.305 |
0.361 |
0.410 |
0.425 |
0.465 |
0.503 |
| 14 |
0.294 |
0.349 |
0.396 |
0.411 |
0.450 |
0.488 |
| 15 |
0.285 |
0.338 |
0.384 |
0.399 |
0.438 |
0.475 |
| 16 |
0.277 |
0.329 |
0.374 |
0.388 |
0.426 |
0.463 |
| 17 |
0.269 |
0.320 |
0.365 |
0.379 |
0.416 |
0.452 |
| 18 |
0.263 |
0.313 |
0.356 |
0.370 |
0.407 |
0.442 |
| 19 |
0.258 |
0.306 |
0.349 |
0.363 |
0.398 |
0.433 |
| 20 |
0.252 |
0.300 |
0.342 |
0.356 |
0.391 |
0.425 |
| 21 |
0.247 |
0.295 |
0.337 |
0.350 |
0.384 |
0.418 |
| 22 |
0.242 |
0.290 |
0.331 |
0.344 |
0.378 |
0.411 |
| 23 |
0.238 |
0.285 |
0.326 |
0.338 |
0.372 |
0.404 |
| 24 |
0.234 |
0.281 |
0.321 |
0.333 |
0.367 |
0.399 |
| 25 |
0.230 |
0.277 |
0.317 |
0.329 |
0.362 |
0.393 |
| 29 |
0.227 |
0.273 |
0.312 |
0.324 |
0.357 |
0.388 |
| 27 |
0.224 |
0.269 |
0.308 |
0.320 |
0.353 |
0.384 |
| 28 |
0.220 |
0.266 |
0.305 |
0.316 |
0.349 |
0.380 |
| 29 |
0.218 |
0.263 |
0.301 |
0.312 |
0.345 |
0.376 |
| 30 |
0.215 |
0.260 |
0.298 |
0.309 |
0.341 |
0.372 |
r11 Q Parameter, where one has two doubtful results on opposite ends
and one is being tested. If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
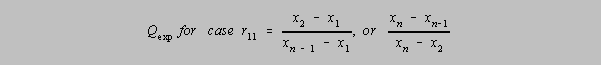
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 4 |
0.910 |
0.955 |
0.977 |
0.981 |
0.991 |
0.995 |
| 5 |
0.728 |
0.807 |
0.863 |
0.876 |
0.916 |
0.937 |
| 6 |
0.609 |
0.689 |
0.748 |
0.763 |
0.805 |
0.839 |
| 7 |
0.530 |
0.610 |
0.673 |
0.689 |
0.740 |
0.782 |
| 8 |
0.479 |
0.554 |
0.615 |
0.631 |
0.683 |
0.725 |
| 9 |
0.441 |
0.512 |
0.570 |
0.587 |
0.635 |
0.677 |
| 10 |
0.409 |
0.477 |
0.534 |
0.551 |
0.597 |
0.639 |
| 11 |
0.385 |
0.450 |
0.505 |
0.521 |
0.566 |
0.606 |
| 12 |
0.367 |
0.428 |
0.481 |
0.498 |
0.541 |
0.580 |
| 13 |
0.350 |
0.410 |
0.461 |
0.477 |
0.520 |
0.558 |
| 14 |
0.336 |
0.395 |
0.445 |
0.460 |
0.502 |
0.539 |
| 15 |
0.323 |
0.381 |
0.430 |
0.445 |
0.486 |
0.522 |
| 16 |
0.313 |
0.369 |
0.417 |
0.432 |
0.472 |
0.508 |
| 17 |
0.303 |
0.359 |
0.406 |
0.420 |
0.460 |
0.495 |
| 18 |
0.295 |
0.349 |
0.396 |
0.410 |
0.449 |
0.484 |
| 19 |
0.288 |
0.341 |
0.386 |
0.400 |
0.439 |
0.473 |
| 20 |
0.282 |
0.334 |
0.379 |
0.392 |
0.430 |
0.464 |
| 21 |
0.276 |
0.327 |
0.371 |
0.384 |
0.421 |
0.455 |
| 22 |
0.270 |
0.320 |
0.364 |
0.377 |
0.414 |
0.446 |
| 23 |
0.265 |
0.314 |
0.357 |
0.371 |
0.407 |
0.439 |
| 24 |
0.260 |
0.309 |
0.352 |
0.365 |
0.400 |
0.432 |
| 25 |
0.255 |
0.304 |
0.346 |
0.359 |
0.394 |
0.426 |
| 26 |
0.250 |
0.299 |
0.341 |
0.354 |
0.389 |
0.420 |
| 27 |
0.246 |
0.295 |
0.337 |
0.349 |
0.383 |
0.414 |
| 28 |
0.243 |
0.291 |
0.332 |
0.344 |
0.378 |
0.409 |
| 29 |
0.239 |
0.287 |
0.328 |
0.340 |
0.374 |
0.404 |
| 30 |
0.236 |
0.283 |
0.324 |
0.336 |
0.369 |
0.399 |
r12 Q Parameter where one has three doubtful results distributed
unevenly and the lone one is tested. If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
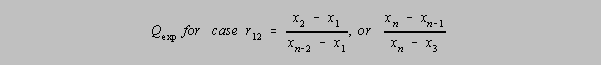
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 5 |
0.919 |
0.960 |
0.980 |
0.984 |
0.992 |
0.996 |
| 6 |
0.745 |
0.824 |
0.878 |
0.891 |
0.925 |
0.951 |
| 7 |
0.636 |
0.712 |
0.773 |
0.791 |
0.836 |
0.875 |
| 8 |
0.557 |
0.632 |
0.692 |
0.708 |
0.760 |
0.797 |
| 9 |
0.504 |
0.580 |
0.639 |
0.656 |
0.702 |
0.739 |
| 10 |
0.464 |
0.537 |
0.594 |
0.610 |
0.655 |
0.694 |
| 11 |
0.431 |
0.502 |
0.559 |
0.575 |
0.619 |
0.658 |
| 12 |
0.406 |
0.473 |
0.529 |
0.546 |
0.590 |
0.629 |
| 13 |
0.387 |
0.451 |
0.505 |
0.521 |
0.564 |
0.602 |
| 14 |
0.369 |
0.432 |
0.485 |
0.501 |
0.542 |
0.580 |
| 15 |
0.354 |
0.416 |
0.467 |
0.482 |
0.523 |
0.560 |
| 16 |
0.341 |
0.401 |
0.452 |
0.467 |
0.508 |
0.544 |
| 17 |
0.330 |
0.388 |
0.438 |
0.453 |
0.493 |
0.529 |
| 18 |
0.320 |
0.377 |
0.426 |
0.440 |
0.480 |
0.516 |
| 19 |
0.311 |
0.367 |
0.415 |
0.429 |
0.469 |
0.504 |
| 20 |
0.303 |
0.358 |
0.405 |
0.419 |
0.458 |
0.493 |
| 21 |
0.296 |
0.349 |
0.396 |
0.410 |
0.449 |
0.483 |
| 22 |
0.290 |
0.342 |
0.388 |
0.402 |
0.440 |
0.474 |
| 23 |
0.284 |
0.336 |
0.381 |
0.394 |
0.432 |
0.465 |
| 24 |
0.278 |
0.330 |
0.374 |
0.387 |
0.423 |
0.457 |
| 25 |
0.273 |
0.324 |
0.368 |
0.381 |
0.417 |
0.450 |
| 26 |
0.268 |
0.319 |
0.362 |
0.375 |
0.411 |
0.443 |
| 27 |
0.263 |
0.314 |
0.357 |
0.370 |
0.405 |
0.437 |
| 28 |
0.259 |
0.309 |
0.352 |
0.365 |
0.399 |
0.431 |
| 29 |
0.255 |
0.305 |
0.347 |
0.360 |
0.394 |
0.426 |
| 30 |
0.251 |
0.301 |
0.343 |
0.355 |
0.389 |
0.420 |
r20 Q Parameter, where one has two doubtful results both located at
the low or high end. If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
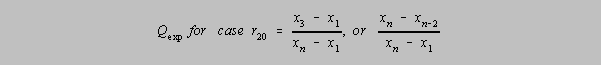
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 4 |
0 935 |
0.967 |
0.983 |
0.987 |
0.992 |
0.996 |
| 5 |
0 782 |
0.845 |
0.890 |
0.901 |
0.929 |
0.950 |
| 6 |
0.670 |
0.736 |
0.786 |
0.800 |
0.836 |
0.865 |
| 7 |
0.596 |
0.661 |
0.716 |
0.732 |
0.778 |
0.814 |
| 8 |
0.545 |
0.607 |
0.657 |
0.670 |
0.710 |
0.746 |
| 9 |
0.505 |
0.565 |
0.614 |
0.627 |
0.667 |
0.700 |
| 10 |
0.474 |
0.531 |
0.579 |
0.592 |
0.632 |
0.664 |
| 11 |
0.449 |
0.504 |
0.551 |
0.564 |
0.603 |
0.627 |
| 12 |
0.429 |
0.481 |
0.527 |
0.540 |
0.579 |
0.612 |
| 13 |
0.411 |
0.461 |
0.506 |
0.520 |
0.557 |
0.590 |
| 14 |
0.395 |
0.445 |
0.489 |
0.502 |
0.538 |
0.571 |
| 15 |
0.382 |
0.430 |
0.473 |
0.486 |
0.522 |
0.554 |
| 16 |
0.370 |
0.418 |
0.460 |
0.472 |
0.508 |
0.539 |
| 17 |
0.359 |
0.406 |
0.447 |
0.460 |
0.495 |
0.526 |
| 18 |
0.350 |
0.397 |
0.437 |
0.449 |
0.484 |
0.514 |
| 19 |
0.341 |
0.387 |
0.427 |
0.439 |
0.473 |
0.503 |
| 20 |
0.333 |
0.378 |
0.418 |
0.430 |
0.464 |
0.494 |
| 21 |
0.326 |
0 37l |
0.4l0 |
0.422 |
0.455 |
0.485 |
| 22 |
0.320 |
0.364 |
0.402 |
0.414 |
0.447 |
0.477 |
| 23 |
0.314 |
0.358 |
0.395 |
0.407 |
0.440 |
0.469 |
| 24 |
0.309 |
0.352 |
0.390 |
0.401 |
0.434 |
0.462 |
| 25 |
0.304 |
0.346 |
0.383 |
0.395 |
0.428 |
0.456 |
| 26 |
0.300 |
0.342 |
0.379 |
0.390 |
0.422 |
0.450 |
| 27 |
0.296 |
0.338 |
0.374 |
0.385 |
0.417 |
0.444 |
| 28 |
0.292 |
0.333 |
0.370 |
0.381 |
0.412 |
0.439 |
| 29 |
0.288 |
0.329 |
0.365 |
0.376 |
0.407 |
0.434 |
| 30 |
0.285 |
0.326 |
0.361 |
0.372 |
0.402 |
0.428 |
r21 Q Parameter, (three doubtful results distributed unevenly; the
furthest of the extreme pair is tested). If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
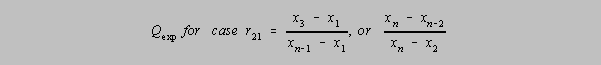
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 5 |
0.952 |
0.976 |
0.987 |
0.990 |
0.995 |
0.998 |
| 6 |
0.821 |
0.872 |
0.913 |
0.924 |
0.951 |
0.970 |
| 7 |
0.725 |
0.780 |
0.828 |
0.842 |
0.885 |
0.919 |
| 8 |
0.650 |
0.710 |
0.763 |
0.780 |
0.829 |
0.868 |
| 9 |
0.594 |
0.657 |
0.710 |
0.725 |
0.776 |
0.816 |
| 10 |
0.551 |
0.612 |
0.664 |
0.678 |
0.726 |
0.760 |
| 11 |
0.517 |
0.576 |
0.625 |
0.638 |
0.679 |
0.713 |
| 12 |
0.490 |
0.546 |
0.592 |
0.605 |
0.642 |
0.675 |
| 13 |
0.467 |
0.521 |
0.565 |
0.578 |
0.615 |
0.649 |
| 14 |
0.448 |
0.501 |
0.544 |
0.556 |
0.593 |
0.627 |
| 15 |
0.431 |
0.483 |
0.525 |
0.537 |
0.574 |
0.607 |
| 16 |
0.416 |
0.467 |
0.509 |
0.521 |
0.557 |
0.580 |
| 17 |
0.403 |
0.453 |
0.495 |
0.507 |
0.542 |
0.573 |
| 18 |
0.391 |
0.440 |
0.482 |
0.494 |
0.529 |
0.559 |
| 19 |
0.380 |
0.428 |
0.469 |
0.482 |
0.517 |
0.547 |
| 20 |
0.371 |
0.419 |
0.460 |
0.472 |
0.506 |
0.536 |
| 10 |
0.363 |
0.410 |
0.450 |
0.462 |
0.496 |
0.526 |
| 22 |
0.356 |
0.402 |
0.441 |
0.453 |
0.487 |
0.517 |
| 23 |
0.349 |
0.395 |
0.434 |
0.445 |
0.479 |
0.509 |
| 24 |
0.343 |
0.388 |
0.427 |
0.438 |
0.471 |
0.501 |
| 25 |
0.337 |
0.382 |
0.420 |
0.431 |
0.464 |
0.493 |
| 26 |
0.331 |
0.376 |
0.414 |
0.424 |
0.457 |
0.486 |
| 27 |
0.325 |
0.370 |
0.407 |
0.418 |
0.450 |
0.479 |
| 28 |
0.320 |
0.365 |
0.402 |
0.412 |
0.444 |
0.472 |
| 29 |
0.316 |
0.360 |
0.396 |
0.406 |
0.438 |
0.466 |
| 30 |
0.312 |
0.355 |
0.391 |
0.401 |
0.433 |
0.460 |
r22 Q Parameter, where one has four doubtful results distributed
evenly
on either side and one is tested. If
Qexp (in the formula below) > Q in the table, then the outlier may be rejected with
that level of confidence.
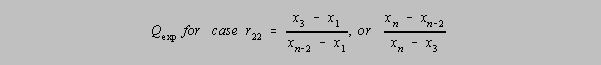
| N |
80%
(alpha=0.20) |
90%
(alpha=0.10) |
95%
(alpha=0.05) |
96%
(alpha=0.04) |
98%
(alpha=0.02) |
99%
(alpha=0.01) |
| 6 |
0.965 |
0.983 |
0.990 |
0.992 |
0.995 |
0.998 |
| 7 |
0.850 |
0.881 |
0.909 |
0.919 |
0.945 |
0.970 |
| 8 |
0.745 |
0.803 |
0.846 |
0.857 |
0.890 |
0.922 |
| 9 |
0.676 |
0.737 |
0.787 |
0.800 |
0.840 |
0.873 |
| 10 |
0.620 |
0.682 |
0.734 |
0.749 |
0.791 |
0.826 |
| 11 |
0.578 |
0.637 |
0.688 |
0.703 |
0.745 |
0.781 |
| 12 |
0.543 |
0.600 |
0.648 |
0.661 |
0.704 |
0.740 |
| 13 |
0.515 |
0.570 |
0.616 |
0.628 |
0.670 |
0.705 |
| 14 |
0.492 |
0.546 |
0.590 |
0.602 |
0.641 |
0.674 |
| 15 |
0.472 |
0.525 |
0.568 |
0.579 |
0.616 |
0.647 |
| 16 |
0.454 |
0.507 |
0.548 |
0.559 |
0.595 |
0.624 |
| 17 |
0.438 |
0.490 |
0.531 |
0.542 |
0.577 |
0.605 |
| 18 |
0.424 |
0.475 |
0.516 |
0.527 |
0.561 |
0.589 |
| 19 |
0.412 |
0.462 |
0.503 |
0.514 |
0.547 |
0.575 |
| 20 |
0.401 |
0.450 |
0.491 |
0.502 |
0.535 |
0.562 |
| 21 |
0.391 |
0.440 |
0.480 |
0.491 |
0.524 |
0.551 |
| 22 |
0.382 |
0.430 |
0.470 |
0.481 |
0.514 |
0.541 |
| 23 |
0.374 |
0.421 |
0.461 |
0.472 |
0.505 |
0.532 |
| 24 |
0.367 |
0.413 |
0.452 |
0.464 |
0.497 |
0.524 |
| 25 |
0.360 |
0.406 |
0.445 |
0.457 |
0.489 |
0.516 |
| 26 |
0.354 |
0.399 |
0.438 |
0.450 |
0.482 |
0.508 |
| 27 |
0.348 |
0.393 |
0.432 |
0.443 |
0.475 |
0.501 |
| 28 |
0.342 |
0.387 |
0.426 |
0.437 |
0.469 |
0.495 |
| 29 |
0 337 |
0.381 |
0.419 |
0.431 |
0.463 |
0.489 |
| 30 |
0.332 |
0.376 |
0.414 |
0.425 |
0.457 |
0.483 |
1. All quotations in this paragraph and the tables of Dixon's Q
parameters at the end of the chapter come from D.B. Rorabacher, Anal. Chem.,
1991, 63, 139.
2. Extracted from D.B. Rorabacher, Anal. Chem.,
1991, 63, 139.
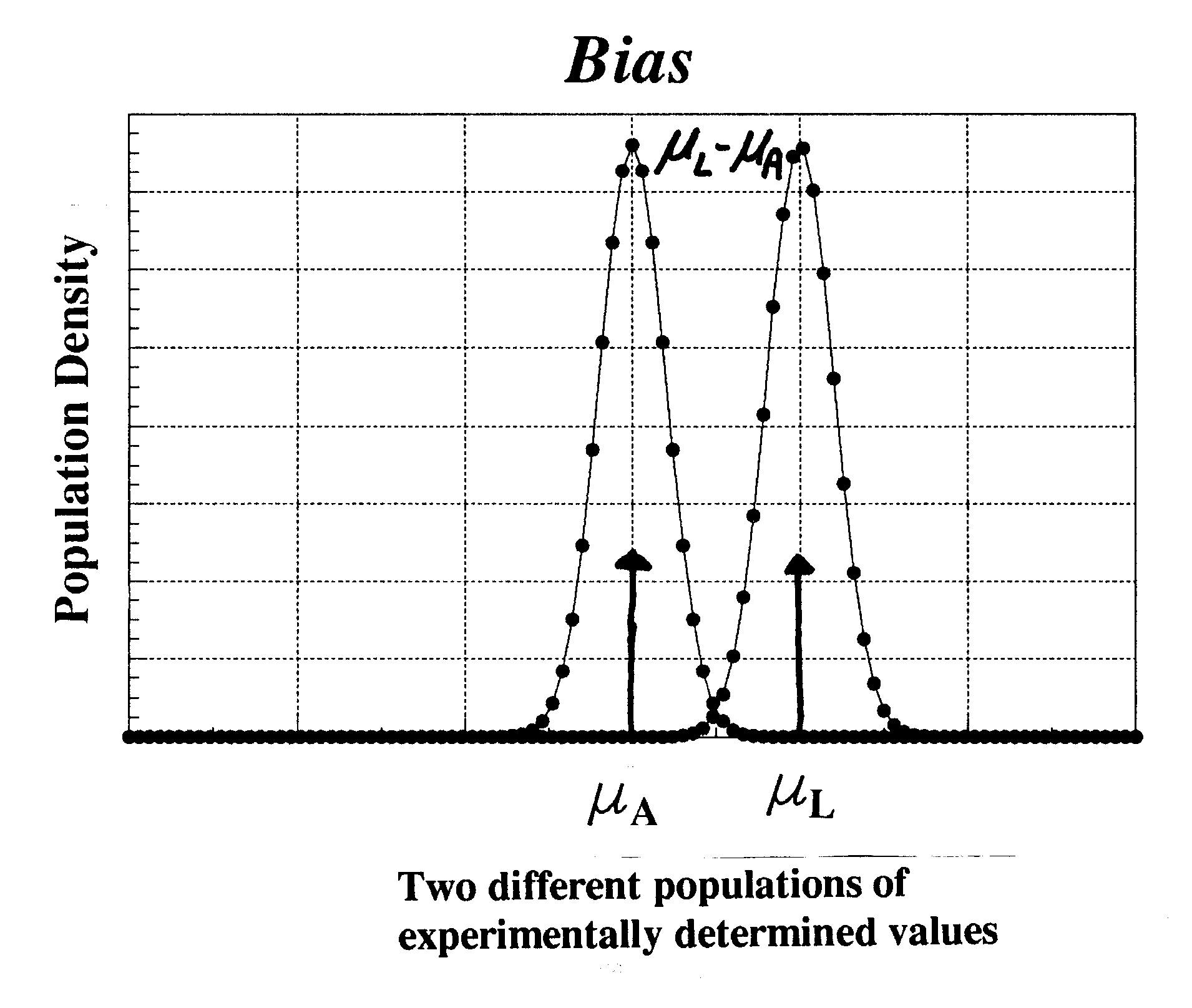 In a most idealized sense, a
value which has been determined experimentally is one element of a population with a normal
distribution. If the method produces a result which is an
acceptable reflection of reality, that is,
if it really works and gives result which reflects that which is
known by some other independent
analysis, then one says that this method does not
produce a significant systematic error. A method
not so reliable and one which routinely produces an
error on the low or high side is said to exhibit
systematic error. Any value obtained using this
second method could be considered, again in a
most idealized sense, to be one element in a
population with a normal distribution. One could
say at the outset that the first method produces an
accurate mean, or µA , whereas the second method produces a lousy mean, or
µL . One then could, graphically, illustrate the two populations
superimposed as shown on the left.
In a most idealized sense, a
value which has been determined experimentally is one element of a population with a normal
distribution. If the method produces a result which is an
acceptable reflection of reality, that is,
if it really works and gives result which reflects that which is
known by some other independent
analysis, then one says that this method does not
produce a significant systematic error. A method
not so reliable and one which routinely produces an
error on the low or high side is said to exhibit
systematic error. Any value obtained using this
second method could be considered, again in a
most idealized sense, to be one element in a
population with a normal distribution. One could
say at the outset that the first method produces an
accurate mean, or µA , whereas the second method produces a lousy mean, or
µL . One then could, graphically, illustrate the two populations
superimposed as shown on the left.